
Abstract/Intro
Attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. Attention 机制要么与 CNN 结合,要么完全替换。
Multiple works try combining CNN-like architectures with self-attention (将 attention 结合到 CNN 中), some replacing the convolutions entirely (将整个卷积网络全部替换成 attention), which while theoretically efficient, have not yet been scaled effectively on modern hardware accelerators due to the use of specialized attention patterns. 理论上可行,但由于使用了专门的注意力模式,在现代硬件加速器上尚未得到有效扩展。
Naive application of self-attention to images would require that each pixel attends to every other pixel. With quadratic cost in the number of pixels, this does not scale to realistic input sizes. 直接对图像使用 attention 会造成大量的不现实计算。
Transformer architecture usage in Vision is limited. A pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. Pre-trained on large amounts of data and transferred to multiply mid-sized or small benchmarks. Transformer 结构在 CV 领域应用不多,ViT 对一系列 image patch 使用 Transformer 取得很好的结果,ViT 在大量数据中做预训练然后迁移到中小数据集。
ViT applies a standard Transformer directly to images, with the fewest possible modifications, by splitting an image into patches and providing the sequence of linear embeddings of these patches as an input to a Transformer. ViT 将图片切分为多个 patch,并将他们序列地作为输入传递给 Transformer。
Transformers lack some of the inductive biases inherent to CNNs, such as translation equivariance and locality, and therefore do not generalize well when trained on insufficient amounts of data. 相较于CNN,Transformer 缺少一定归纳偏执 inductive biases,如 locality,平移不变性 translation equivalence ,的先验信息,使 ViT 在数据不足的情况下的泛化能力不是很好。
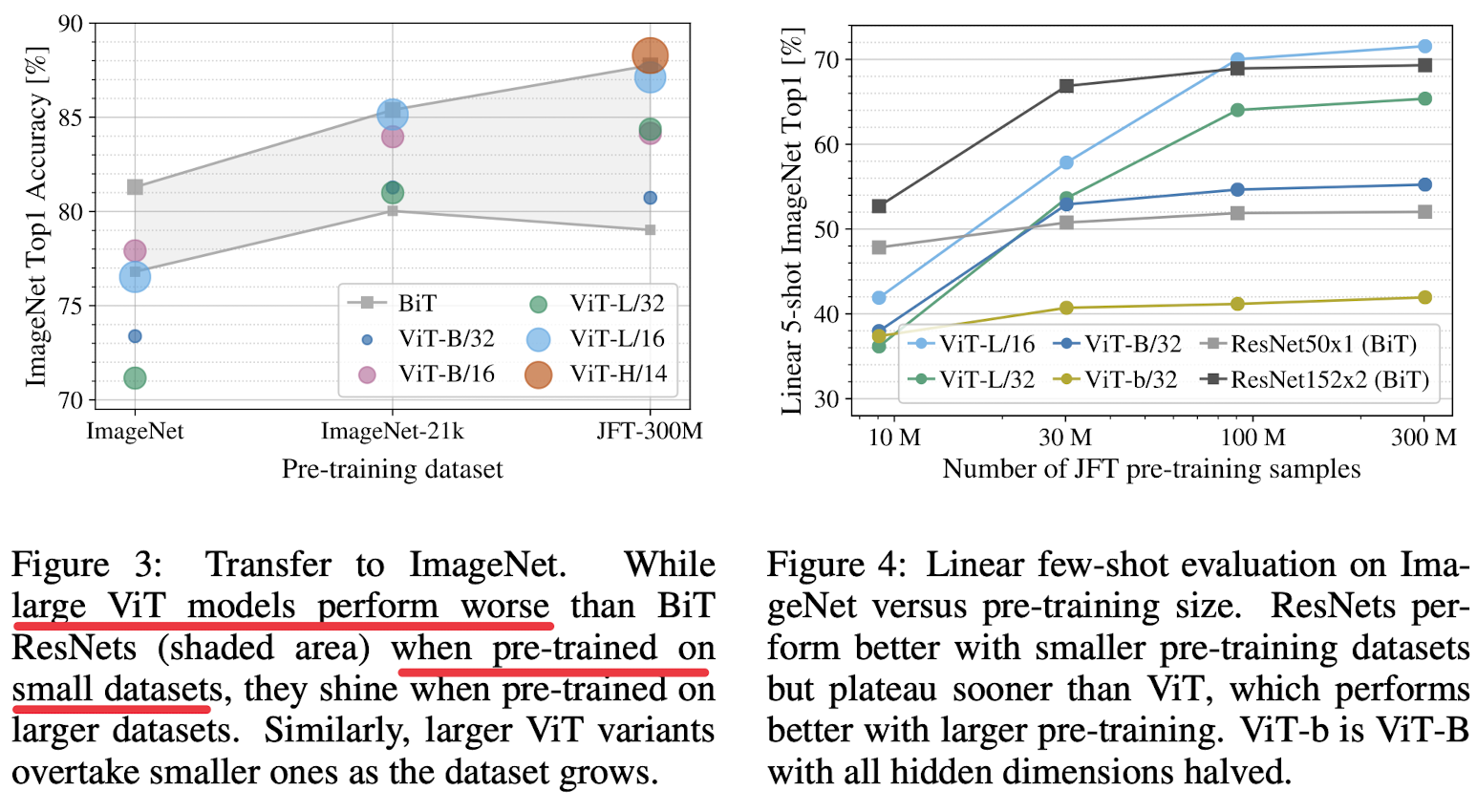
Method
ViT follows the original Transformer as closely as possible.
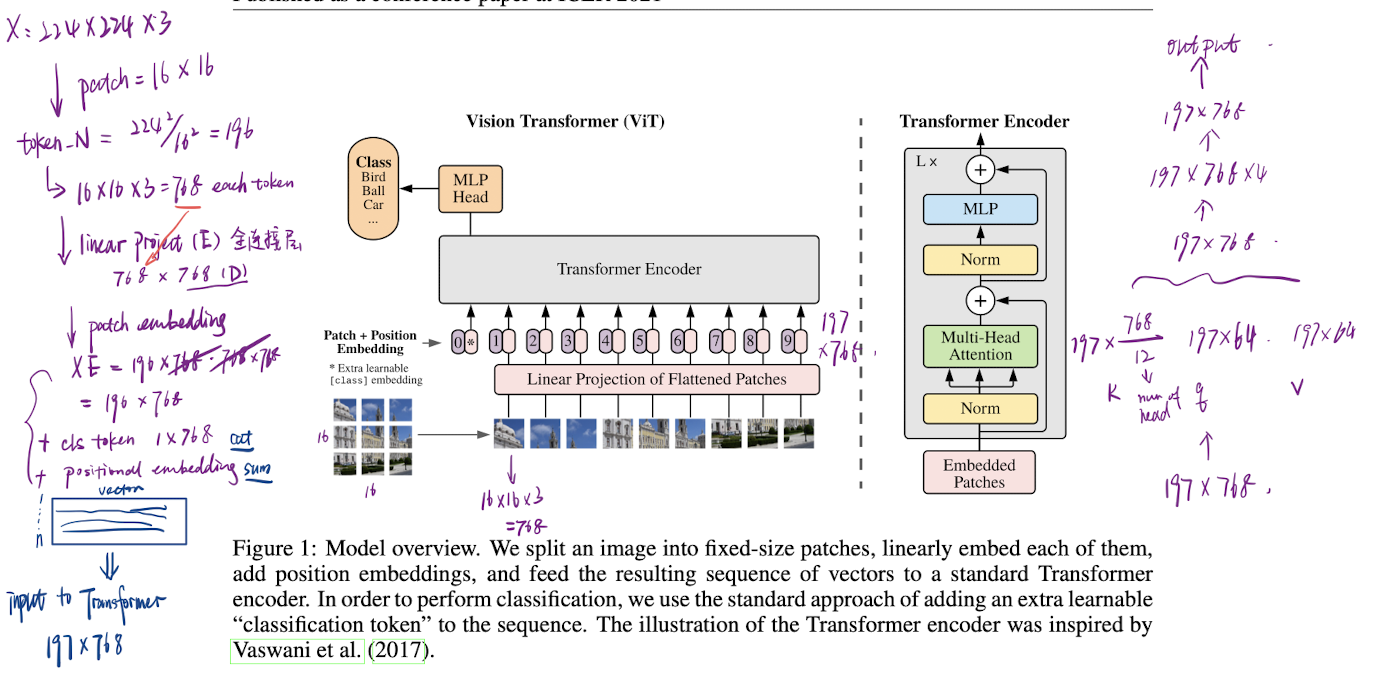
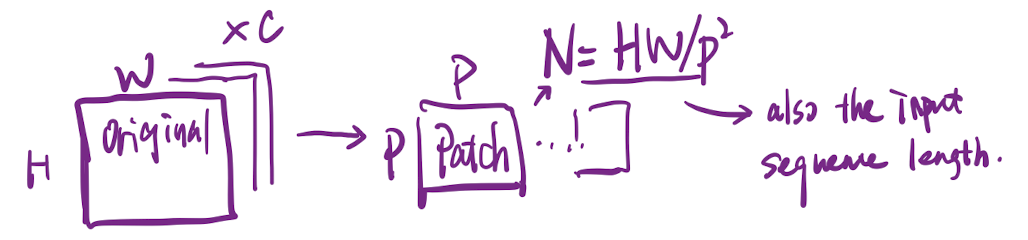
The standard Transformer receives as input a 1D sequence of token embeddings. To handle 2D images, reshape the image into a sequence of flattened 2D patches , 为了处理 2D 图像,将 图像切分为 个 大小的 patches,展平 (flattened) 后传入 Transformer。
- where is the resolution of the original image,
- is the channel numbers,
- is the resolution of each image patch,
- and is the resulting number of patches, also the effective input sequence length for the Transformer
Flatten the patches and map to dimensions with a trainable linear projection, as Transformer uses constant latent vector size through all the layers. Refer the output of the projections as the patch embeddings. 将图像 patches 展平,并映射到 维,作为输入。
Prepend a learnable embedding to the sequence of the embedded patches , whose output serves as the image representation . The classification head is implemented by a MLP with one hidden layer at pre-training time and by a single linear layer at fine-tuning time, (concat to the first). 在输入的最前面添加一个 embedding 作为分类头。
Position embedding are added to the patch embeddings to retain positional information. Use standard learnable 1D position embeddings, since no significant performance gains from using 2D-aware position embeddings. 用 1D 的位置编码以保留位置信息,即每个 patch 在图片中的顺序位置。位置编码信息直接 sum 到输入 embedding。
The resulting sequence of embedding vectors serves as input to the encoder. (sum)
The Transformer encoder consists of alternating layers of multi-headed self- attention (MSA) and MLP blocks. LayerNorm (LN) is applied before every block, and residual connections after every block . The MLP contains two layers with a GELU non-linearity. Transformer Encoder 包含 多头自注意力层、MLP 层,每个模块包含 LayerNorm (pre-norm) 和 残差链接。MLP 层用 GeLU 作为激活函数。
Inductive biases Vision Transformer has much less image-specific inductive bias than CNNs. ViT 相比 CNN 具有更少的图像特定归纳偏置。
- In CNNs, locality, two-dimensional neighbourhood structure, and translation equivariance are baked into each layer throughout the whole model. 在 CNN 中,局部性、二维邻域结构以及平移等价性是“内置”于模型每一层中的
- CNN的归纳偏置: • 局部性:CNN 中的卷积操作只关注局部邻域的信息,这符合图像中相邻像素之间通常存在较强相关性的实际情况。 • 二维邻域结构:图像具有二维结构,CNN 在设计中充分利用了这一点,其卷积核在二维平面上滑动捕捉特征。 • 平移等价性:卷积操作保证了如果图像平移,其特征响应也会相应平移,使得模型对图像中物体位置的变化具有鲁棒性。
- In ViT, only MLP layers are local and translationally equivariant, while the self-attention layers are global. 在 ViT 中,只有 MLP(多层感知机)层具有局部性和平移等价性,而自注意力层则是全局的。
这种设计的差异意味着: • CNN 在处理图像时会利用大量关于图像结构的先验知识,因此在样本量较少时可能更高效。 • ViT 则更多地依赖于大量数据来学习这些结构,因为它没有那么多内置的图像特定假设。
Model Recipe
