Main contributions
- implement window attention in the visual encoder to optimize inference efficiency
- introduce dynamic FPS sampling, extending dynamic resolution to the temporal dimension and enabling comprehensive video understanding across varied sampling rates
- upgrade MRoPE in the temporal domain by aligning to absolute time
- high quality data for pre-training and SFT
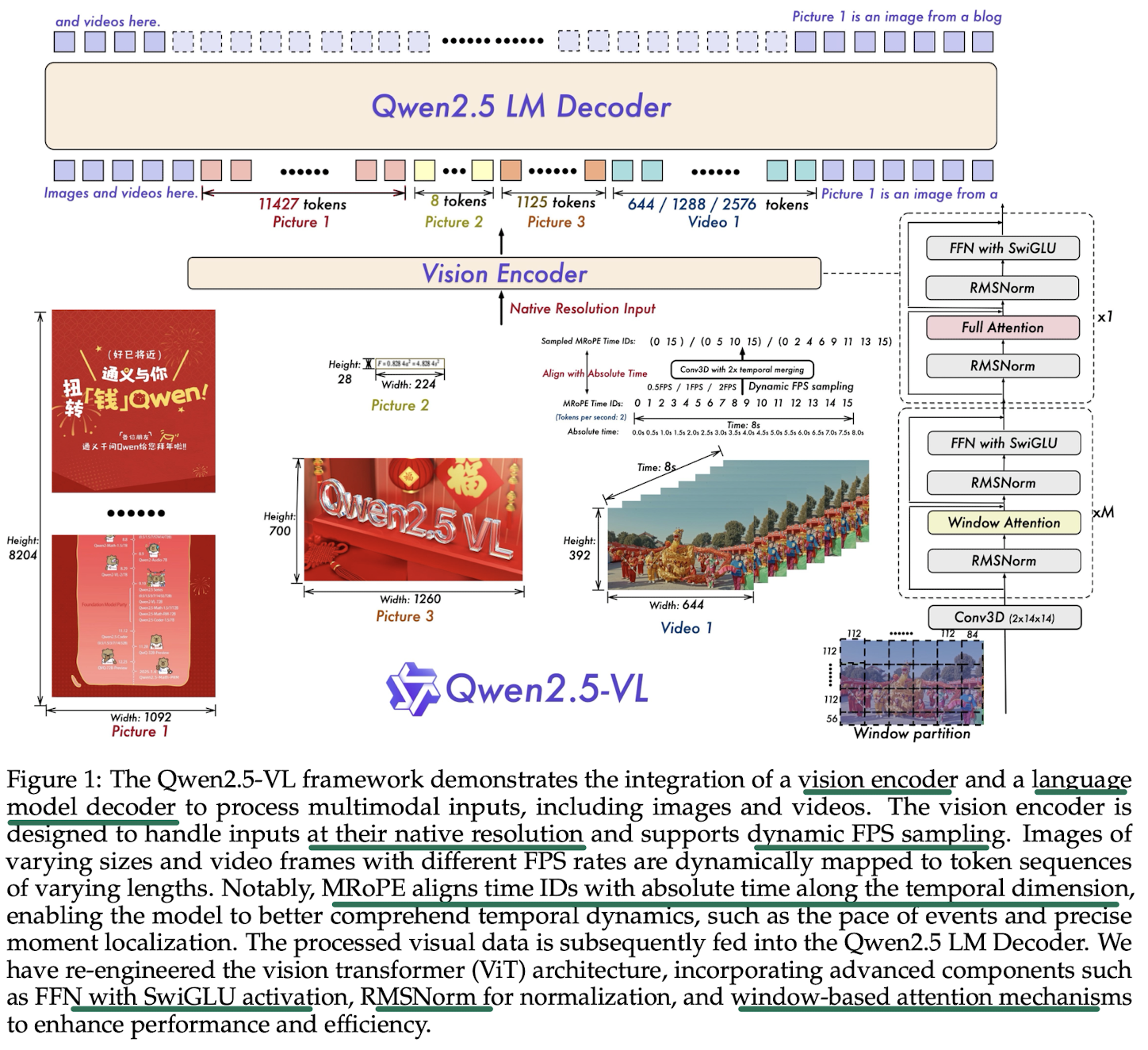
Approach
Model Architecture
Large Language Model:
- initialized with pre-trained weights from the Qwen2.5 LLM
- modify 1D RoPE to Multimodal Rotary Position Embedding Aligned to Absolute Time Vision Encoder
- a redesigned ViT architecture
- 2D-RoPE
- window attention
- the height and width of input images are resized to multiples of 28 before fed into ViT
- split the images into patches with a stride of 14 MLP-based Vision-Language Merger
- group spatially adjacent sets of 4 patch features, then concatenated and passed the grouped features through a 2-layer MLP to project them into a dimension that aligns with the text embeddings used in LLM projector 由两层 MLP 构成,在此之前还做了空间降采样,将 token长度缩小了四倍
- reduce computational costs and provides a flexible way to dynamically compress image feature sequences of varying length
Vision Encoder
Windowed attention: ensures the computational cost scales linearly with the number of patches rather than quadratically 确保计算成本随着 patch 数量线性增长,较大的图像有更多数量的 tokens,而非二次方增长。
- Only 4 layers employ full self-attention, the rest use windowed attention with a maximum window size of (corresponding to patches) 只有 4 层使用全自注意力,其余层用窗口大小最大为 (对应 的块) 的窗口自注意力
- 图像被切成不重叠的窗口,每个窗口内的 patch 之间计算attention,但不与其他窗口的 patch 计算。多个 windows attention 块之后,添加了一个完整的 full attention 块来增强全局信息捕捉。
- regions smaller than are processed without padding, preserving original resolution 小于 的区域 不加 padding 保留原有分辨率
Positional Encoding 2D RoPE to capture spatial relationships in 2D space. 3D patch partitioning to handle video inputs.
- images patches as the basic unit 对图片输入,以 的块为基础单元
- two consecutive frames are grouped together, to reduce the number of tokens fed to LLMs 对视频输入,相连的两帧分在一组,减少送入 LLM 的 token 数量
- adopt RMSNorm for normalization, and SwiGLU as the activation function.
Train the redesigned ViT from scratch 重新训练 ViT, consists of
- CLIP pre-training
- vision-language alignment
- end-to-end fine-tuning
Images are randomly sampled according to their original aspect ratios, enabling the model to generalize effectively to inputs of diverse resolutions. 随机抽取保持原始纵横比的图像,使模型能够有效地泛化到不同分辨率的输入。 这种方法允许模型在训练和推理阶段处理不同分辨率和纵横比的图像,提高了其在各种计算机视觉任务中的性能和灵活性。
Native Dynamic Resolution and Frame Rate
Spatial domain
- dynamically converts images of varying sizes into sequences of tokens with corresponding lengths 动态地将不同大小的图像转换为长度相应的 token 序列
- uses the actual dimensions of the input images to represent bounding boxes, points, and other spatial features, improves the model ability to process images across different resolutions 使用输入图像的实际尺寸来表示边界框、点和其他空间特征,提高了模型处理不同分辨率图像的能力。
Video inputs
- use dynamic frame rate (FPS) training and absolute time encoding
- the model can better capture temporal dynamics of video content by adapting to variable frame rates 使模型能够适应可变帧率,更好地捕捉视频内容的时间动态
- aligns MRoPE IDs directly with the timestamps, allows model to understand the tempo of time through the intervals between temporal dimensions IDs, without necessitating any additional computational overhead 通过将 mRoPE(多模态旋转位置嵌入)ID直接与时间戳对齐,模型能够 通过时间维度 ID 之间的间隔来理解时间节奏,无需额外的计算开销。
Multimodal Rotary Position Embedding Aligned to Absolute Time
mRoPE in Qwen2.5-vl aligns the temporal component with absolute time.
The model can learn consistent temporal alignment across videos with different FPS sampling rate by leveraging the intervals between temporal IDs. 通过利用时间标识符之间的间隔,模型可以在不同帧率采样的视频中学习一致的时间对齐。