DeepSeek VL
Three key dimensions of the approaches:
- data construction: diverse, scalable, extensively covers real-world scenarios, knowledge-based contents
- model architecture:
- a hybrid vision encoder that efficiently processes high-resolution images within a fixed token budget
- training strategy
Data
- vision-language pretraining data: warm up the vision-language adaptor in training stage 1, jointly pretrain the vlm in stage 2
- vision-language SFT data: in training stage 3
Approach
Architecture
The system contains: a hybrid vision encoder, a vision adaptor, and a language model.
Hybrid Vision Encoder
A single SigLIP encoder struggles to address all real-world questions comprehensively. Because
- clip family are designed for semantic visual representations but challenged by ambiguous encoding
- clip models are limited by its relatively low-resolution inputs
The hybrid vision encoder combines the SAM-B and SigLIP-L encoders 结合了高分辨率的 SAM-B 编码器与低分辨率的 SigLIP-L 编码器,以在固定的 token 预算内既保留细节信息,又提取丰富的语义特征。
- SAM-B: a pre-trained ViTDet image encoder to process low-level features, which accepts high-resolution 1024x1024 image inputs 输入图像首先被 SAM-B 编码器(基于 ViTDet)缩放至 1024×1024,并生成一个 64×64×256 的特征图
- SigLIP-L: for low-resolution 384x384 image inputs
- 高分辨率特征提取(SAM-B)
- A high-resolution SAM-B vision encoder first resizes the image into 1024x1024 and results in a 64x64x256 feature map. 输入图像首先被 SAM-B 缩放至 1024×1024,并生成一个 64×64×256 的特征图 。
- SAM-B 专注于捕捉细粒度的低级视觉信息,如小物体轮廓、文本边缘等,弥补 CLIP 系列模型在高分辨率下的局限性(CLIP 常见输入分辨率仅 224–512) 。
- 特征下采样与重排(VL Adaptor)
- The VL Adaptor initially interpolates it into a size of 96x96x256. It employs two CNN with a stride of 2, producing a feature map of 24x24x1024, and reshapes it to 576x1024. 将上一步获得的 64×64×256 特征图先双线性插值(interpolation)至 96×96×256,再通过两层步幅为 2 的卷积层(stride=2)降采样,得到 24×24×1024 的特征图,并将其重塑(reshape)为 576×1024 。
- 该过程在保证足够感受野的同时,有效控制序列长度,为后续与语言模型的融合提供合适的输入规模。
- 低分辨率语义提取(SigLIP-L)
- Alongside, the low-resolution feature map of size 576x1024 generated by SigLIP-L is concatenated with the high-resolution features, resulting in 576 visual tokens with 2048 dimensions. 并行地,SigLIP-L 接收 384×384 的低分辨率图像,提取高层次的语义特征,并同样生成一个 576×1024 的特征表示 。
- The visual tokens possess a substantial capacity for enhancing high-level semantic visual recognition and low-level visual grounding tasks.
- SigLIP 系列专注于语义对齐,能够有效捕捉全局语义信息,但对细节的分辨力不足,故需与 SAM-B 互补。
- 特征拼接与激活
- Then undergo GeLU and are directed through an embedding layer to establish a connection with the LLM. 将两路特征在 token 维度上拼接,得到形状为 576×2048 的视觉 token 序列。
- 对拼接后的特征应用 GeLU 激活,并通过一层嵌入(embedding)层映射到语言模型的输入空间,完成视觉-语言对齐 。
Vision-Language Adaptor
A two-layer hybrid MLP to bridge the vision encoder and the LLM.
- MLP-1: process high- and low-resolution features separately
- MLP-2: concatenated the features along their dimensions and then transformed into the LLM's input space
- 由两层混合 MLP 构成,首先对高分辨率与低分辨率特征分别进行单层线性映射,然后在特征维度拼接后,再通过第二层 MLP 转换到 LLM 的嵌入空间。
Language Model
DeepSeek LLM.
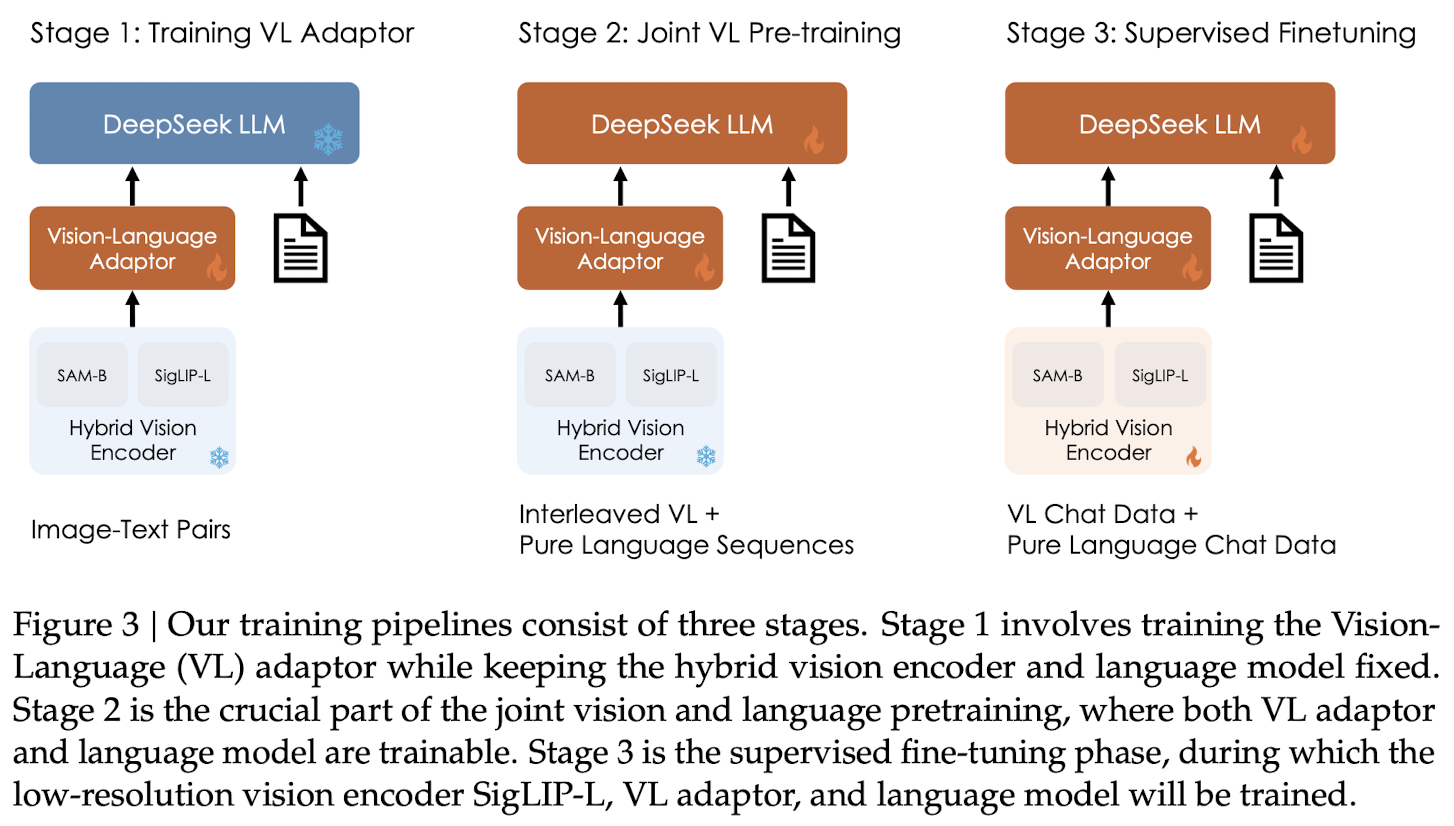
Training Pipeline
Three consecutive stages:
 currently focus on visual understanding capabilities and only calculate the next token prediction loss on the language part
currently focus on visual understanding capabilities and only calculate the next token prediction loss on the language part
Stage 1: Training Vision-Language Adaptor
Build a conceptual link between visual and linguistic elements within the embedding space.
Both the vision encoder and the LLM remain frozen during this stage, while solely allowing the trainable parameters within the vision-language adaptor.
Expanding the data scale at this stage doesn't provide benefits and may even lead to inferior performance.
Stage 2: Joint Vision-Language pretraining
An additional stage to enable LLMs to comprehend multimodal inputs. Freeze the vision encoder and optimize the language model and VL adaptor.
Directly train the LLM with multimodal data has a trade-off between enhancing multimodal abilities and preserving linguistic proficiency, hypothesize factors:
- multimodal corpora divergence from the complexity and distribution of linguistic data 大多数多模态语料过于简单,与语言数据的复杂性和分布存在显著差异
- a competitive dynamic between multimodal and linguistic modalities, leading to catastrophic forgetting 多模态与语言模态之间似乎存在一种竞争动态,导致大型语言模型的语言能力发生灾难性遗忘
Joint Language-multimodal Training: Engage both multimodal data and a large proportion of language data into the training.
- language:multimodal = 7:3
Stage 3: SFT
Finetune the pretrained DeepSeek-VL model with instruction-based fine-tuning to bolster its ability to follow instructions and engage in dialogue, culminating in the creation of the interactive DeepSeek-VL-Chat model.
Optimize the language model, the adaptor, and the hybrid vision encoder with the vision-language SFT data. Freeze the SAM-B.
Supervise answers and special tokens and mask the system and user prompts.
DeepSeek VL 2
 DeepSeek-VL2 is a series of large MoE VLM.
DeepSeek-VL2 is a series of large MoE VLM.
- vision component: incorporate a dynamic tiling vision encoding strategy designed for processing high-resolution image with different aspect ratios.
- language component: leverage DeepSeekMoE models with the MLA
- dataset improved
Model Architecture
VL2 consists of 3 core modules:
- a vision encoder
- a vision-language adaptor
- a MoE LM