GLM-4.1V-Thinking (9B base/thinking) is a VLM designed to advance general-purpose multimodal reasoning. The model gains the upper capability through large scale pretraining and then RL with Curriculum Sampling (RLCS).
Intro
GLM-4.1V-Thinking's training framework is structured around a unified objective, to comprehensively enhance the model's reasoning capabilities through scalable RL.
The pretraining curated a broad and diverse corpus of knowledge-intensive multimodal data and the SFT stage also used carefully designed, domain-specific datasets. The RL phase is conducted with the new introduced RLCS.
RLCS is a multi-domain RL framework that combines curriculum learning with difficulty-aware sampling to improve training efficiency by selecting tasks and samples suited to the model's current competence.
Key findings
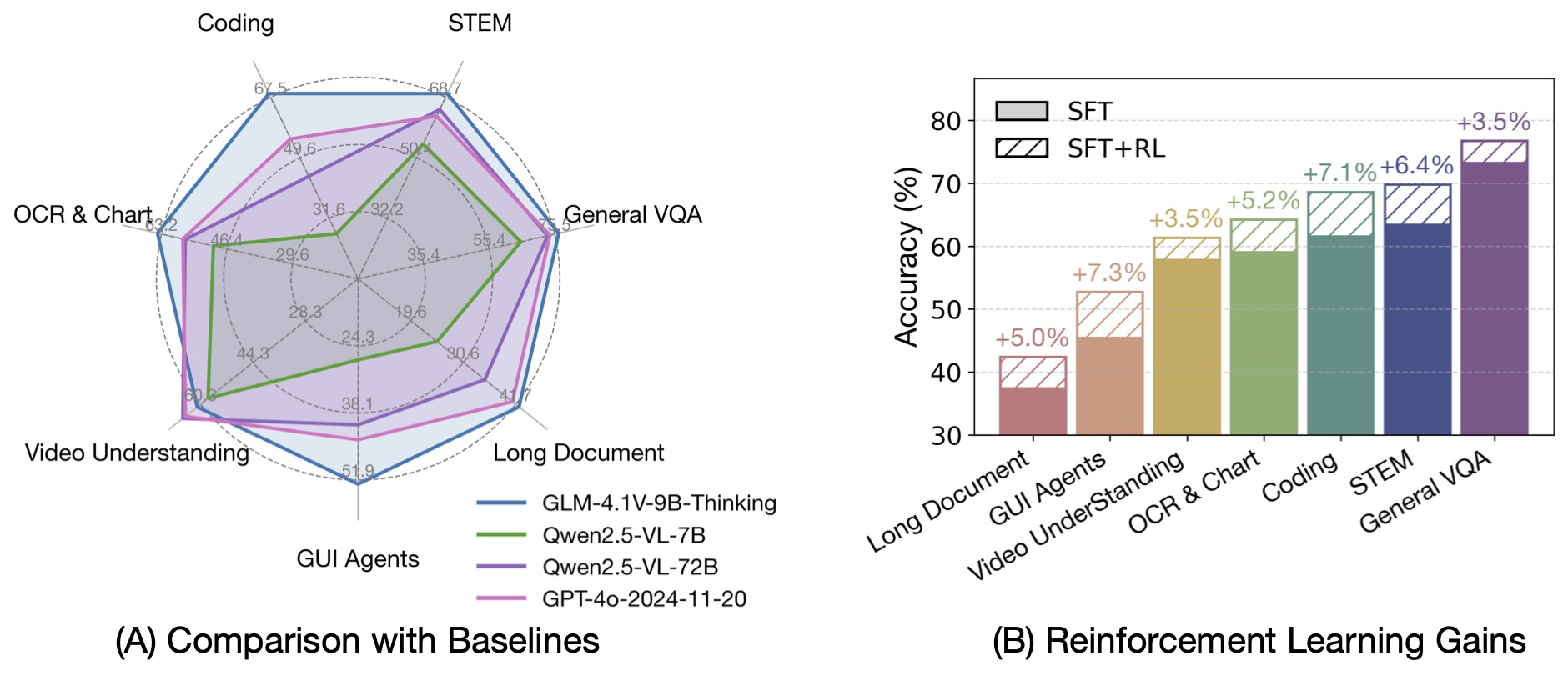
- Multi-domain reinforcement learning demonstrates robust cross-domain generalization and mutual facilitation.
- Dynamically selecting the most informative rollout problems is essential for both efficiency and performance.
- A robust and precise reward system is critical for multi-domain RL.
Architecture
The architecture contains 3 components:
- a vision encoder: AIMv2-Huge
- 3D convolutions, enables temporal downsampling by a factor of 2 for video inputs (duplicate single-image inputs)
- an MLP adapter
- a LLM: GLM

For arbitrary image resolution and aspect ratios,
- 2D RoPE, enables the model to effectively process images with extreme aspect ratios (over 200:1) or high resolution (beyond 4K)
- Retrain the original learnable absolute position embeddings of the pre-trained ViT
The embeddings are dynamically adapted to variable-resolution inputs via bicubic interpolation. For an input image, divide into a grid of patches, the integer coordinates of each patch are first normalized to a continuous grid spanning :
The normalized coordinates are then used to sample from the original position embedding table using a bicubic interpolation function to generate the final adapted embedding for the patch
Extend RoPE to 3D-RoPE in the LLM for spatial awareness on the language side.
For videos, insert a time index token after each frame token, where the time index is implemented by encoding each frame’s timestamp as a string. Unlike multi-image inputs, video frames form a temporally coherent sequence.