CV systems that are trained to predict a fixed set of predetermined object categories are restricted from the supervision limitations of generality and usability.
Simple pre-training task of predicting which caption goes with which image is efficient and scalable to learn image representation from (image, text) pair. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks.
Intro
Image classifiers trained with natural language supervision at large scale. A new dataset of 400m (image, text) pairs, and trained CLIP (Contrastive Language-Image Pre-training).
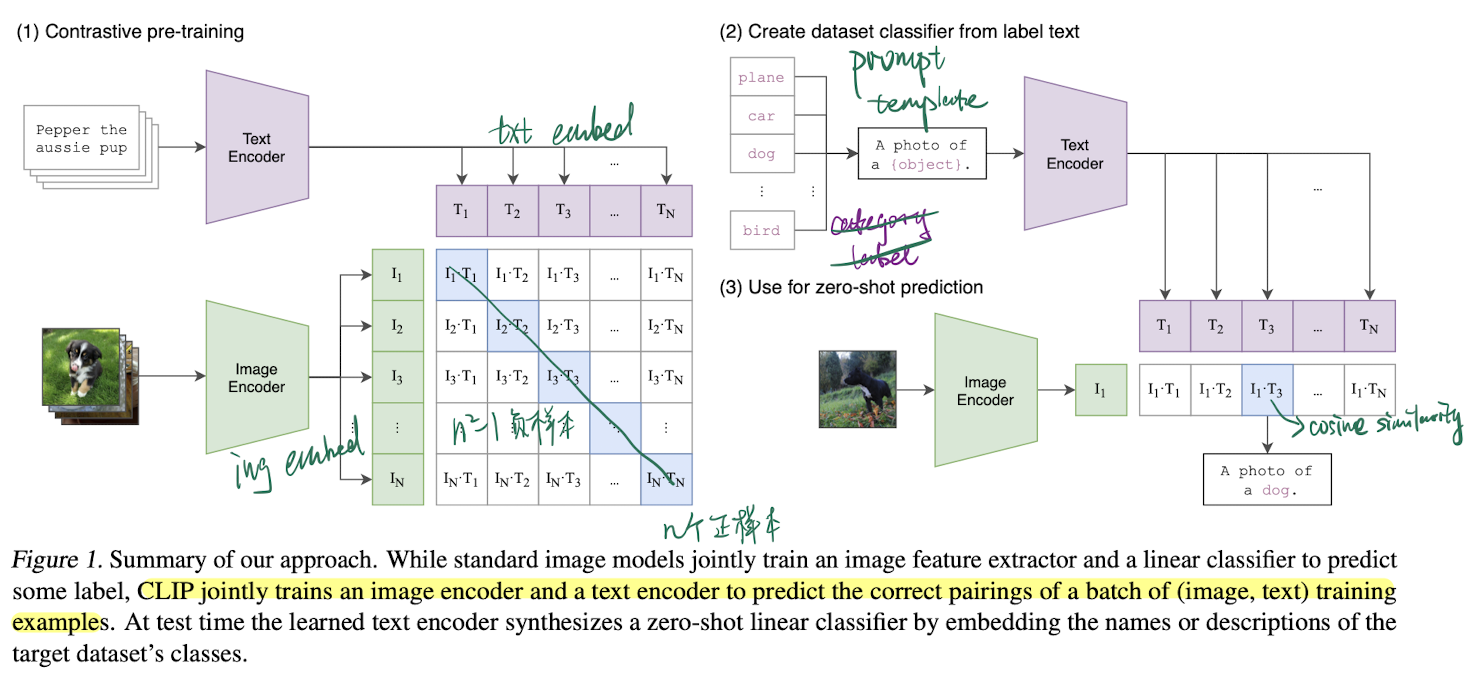
Approach
Natural Language Supervision
At the core of approach is the idea of learning perception from supervision contained in natural language, 通过自然语言中的监督信号来学习感知能力. Use natural language as a training signal, learning from natural language supervision, 利用自然语言作为训练信号,从中获取监督信息进行学习.
- easier to scale natural language supervision compared to standard crowd-sourced labeling for image classification since it does not require annotations to be in a classic “machine learning compatible format” such as the canonical 1-of-N majority vote “gold label” 自然语言监督比传统的图像分类标注更容易扩展,无需标注信息
- learns a representation and also connects that representation to language which enables flexible zero-shot transfer 不仅学习了对数据的表示,还将这种表示与自然语言关联起来,可以更灵活地进行 零样本迁移(zero-shot transfer),即在没有专门为某个任务提供训练数据的情况下,模型仍然可以完成该任务
Creating a Sufficiently Large Dataset
Build a new datasets as the rest are either low in amount or bad in annotation.
Selecting an Efficient Pre-Training Method
Training efficiency was key to successfully scaling natural language supervision. Try to predict the exact words of the text accompanying each image is a difficult task.
Contrastive representation learning for images has found that contrastive objectives can learn better representations than their equivalent predictive objective. 图像的对比表示学习发现,对比目标 比其等效的预测目标能够学习到更好的表示。Generative models require more computation resources for better performance. Contrastive objective is to training a system to solve the potentially easier proxy task of predicting only which text as a whole is paired with which image (正例) and not the exact words of that text (负例). 对比目标(contrastive objective)是一种训练方法,其核心是让模型学会区分正例(正确匹配的图像和文本对)和负例(错误匹配的图像和文本对)。通过这种方式,模型学习到如何将正确的图像和文本配对,而不需要精确地预测文本的具体内容。
Given a batch of (image, text) pairs, CLIP is trained to predict which of the possible (image, text) pairings across a batch actually occurred.
- a multimodal embedding space by jointly training an image encoder and text encoder to
- maximize the cosine similarity of the image and text embeddings of the real pairs in the batch 最大化匹配正例之间的 cosine similarity
- while minimizing the cosine similarity of the embeddings of the incorrect pairings 最小化不匹配的负例之间的 cosine similarity
- optimize a symmetric cross entropy loss over these similarity scores 计算两个维度的交叉熵,即 image 投射到 text 空间 和 text 投射到 image 空间 后预测到概率分布,希望两个分布都与预期分布相近,最后两个 loss 求平均
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2 # InfoNCE loss- over-fitting is not a major concern
- training details are simplified
- train CLIP from scratch without initializing the image encoder with ImageNet weights or the text encoder with pre-trained weights
- use only a linear projection to map from each encoder’s representation to the multi-modal embedding space, instead of using non-linear projections 只用了 线性变换 将 encoder 映射到多模态向量空间
- remove the text transformation function that samples a single sentence at uniform from the text since many of the (image, text) pairs in CLIP’s pretraining dataset are only a single sentence
- simplify the image transformation function
- random square crop from resized images is the only data augmentation 数据增强只用了随机裁切
- set temperature parameter that controls the range of the logits in the softmax as a scalar hyperparameter
Choosing and Scaling a Model
Image Encoder
- ResNet-50
- use ResNet-D improvements and the antialiased rect-2 blur pooling
- replace the global average pooling layer with an attention pooling mechanism The attention pooling is implemented as a single layer of “transformer-style” multi-head QKV attention where the query is conditioned on the global average-pooled representation of the image
- ViT
- adding an additional layer normalization to the combined patch and position embeddings before the transformer
- and use a slightly different initialization scheme
Text Encoder Transformer with some architecture modifications that operates on a lower-cased byte pair encoding (BPE) representation of the text with a 49,152 vocab size. Base size of 63M-parameters 12 layers 512-wide model with 8 heads.
- max sequence length is 76 for computational efficiency
- text sequence is bracketed with and tokens
- activations of the highest layer of the transformer at the token are treated as the feature representation of the text which is layer normalized and then linearly projected into the multi-modal embedding space
- masked self-attention was used in the text encoder to preserve the ability to initialize with a pre-trained language model or add language modeling as an auxiliary objective
only scale the width of the model to be proportional to the calculated increase in width of the ResNet and do not scale the depth at all
Zero-shot Transfer
In computer vision, zero-shot learning usually refers to the study of generalizing to unseen object categories in image classification. CLIP changes the term to study generalization to unseen datasets.
CLIP motivated studying zero-shot transfer as a way of measuring the task-learning capabilities of machine learning systems.
Using CLIP for zero-shot transfer
CLIP is pre-trained to predict if an image and a text snippet are paired together in its dataset.
- compute the feature embedding of the image and the feature embedding of the set of possible texts by their respective encoders
- calculate the cosine similarity, scale by a temperature parameter , normalized into a probability distribution via a softmax
- the prediction layer is a multinomial logistic regression classifier with L2-normalized inputs, L2-normalized weights, no bias, and temperature scaling
For zero-shot evaluation, we cache the zero-shot classifier once it has been computed by the text encoder and reuse it for all subsequent predictions.
Representation Learning
It is more common to study the representation learning capabilities of a model. 在下游任务中使用所有数据训练。
- Linear Probe: Fitting a linear classifier on a representation extracted from the model and measuring its performance on various datasets is a common approach.
- Fine-tuning: measuring the performance of end-to-end fine-tuning of the model
- more flexible and proved to be better than linear classification on most image classification datasets
Still choose Linear Probe:
- CLIP is focused on developing a high-performing task and dataset-agnostic pre-training approach
- For CLIP, training supervised linear classifiers has the added benefit of being very similar to the approach used for its zero-shot classifiers which enables extensive comparisons and analysis
- linear classifiers require minimal hyper-parameter tuning and have standardized implementations and evaluation procedures.
Fine-tuning on the other hand:
- adapts representations to each dataset during the fine-tuning phase, can compensate for and potentially mask failures to learn general and robust representations during the pre-training phase.
- CLIP aimed to compare CLIP to a comprehensive set of existing models across many tasks, fine-tuning is difficult to fairly evaluate and computationally expensive to compare a diverse set of techniques as discussed in other large scale empirical studies
CLIP models learn a wider set of tasks than has previously been demonstrated in a single computer vision model trained end-to-end from random initialization CLIP vision transformers are about 3x more compute efficient than CLIP ResNets. All CLIP models, regardless of scale, outperform all evaluated systems in terms of compute efficiency.
Limitations
- the performance of zero-shot CLIP is on average competitive with the simple supervised baseline of a linear classifier on top of ResNet-50 features
- CLIP’s zero-shot performance is still quite weak on several kinds of tasks, struggles with more abstract and systematic tasks
- zero-shot CLIP still generalizes poorly to data that is truly out-of-distribution for it
- CLIP does little to address the underlying problem of brittle generalization of deep learning models
- ...