Model Architecture
Vision encoder + MLP-based vision-language merger + LLM

LLM
- 4 dense variants(2/4/8/32B) and 2 MoE variants(30B-A3B, 235B-A22B)
- Qwen3 backbones
Vision Encoder
- SigLIP-2 architecture, continue training with dynamic input resolutions, initialized from official pretrained checkpoints
- 2D-RoPE and interpolate absolute position embeddings based on input size, following CoMP
- default SigLIP2-SO-400M and SigLIP2-Large(300M) for small-scale LLMs(2/4B)
MLP-based Vision-Language Merger
- a two-layer MLP to compress 2x2 visual features from the vision encoder into a single visual token, aligned with the LLM's hidden dimension
- deploy specialized mergers to support the DeepStack mechanism
Interleaved MRoPE
The MRoPE in Qwen2 has imbalanced frequency spectrum(频率谱不均衡) problem, which degrade performance on long-video understanding benchmarks. 削弱模型在长视频理解上的效果
Qwen3 redesign the frequency allocation by interleaving the , and components across the embedding dimensions. This ensures that each spatial-temporal axis is uniformly represented across both low- and high-frequency bands. 通过在 embedding 维度上 交错地为时间 、高度 、宽度 分配频率,让三个轴在低频到高频的整个频率范围上都均匀出现,各个空间-时间轴都能同时获得低频(全局信息)和高频(局部细节)表示。
低维索引对应的频率值更大,所以高频分量的相邻位置编码值差异更大;如果高频分量丢失,相邻位置编码值就会变小。即:高频分量对应低纬度索引。
MRoPE 的排列方式按 , , 排列 Interleaved MRoPE 的排列方式为三者交错 每一条轴 都能覆盖从低频到高频的一整条频率谱,时间轴既能表示非常长的全局变化,也能表示很短的局部细节,时间、高度、宽度的频率分布更均匀。
DeepStack
Inject visual tokens into multiple layers of LLM. Extend DeepStack to extract visual tokens from intermediate layers of the ViT, preserving rich visual information, ranging from low- to high-level representations.
- select features form 3 distinct levels of the vision encoder
- dedicated vision-language merger modules project these multi-level features into visual tokens
- then added directly to the corresponding hidden states of the first 3 LLM layers
与 DeepStack 类似,将视觉 token 注入 LLM 的多个层中。在 Qwen3-VL 中,我们进一步扩展 DeepStack:从 ViT 的中间层提取视觉 token,从而保留从低层到高层的丰富视觉表征。
- 从视觉编码器的 三个不同层级(浅层 / 中层 / 深层)选择特征;
- 通过专门设计的 视觉-语言融合模块,把这些多层特征投影成统一格式的视觉 token;
- 然后把这些视觉 token 直接加到 LLM 前三层的 hidden states 上。
Video Timestamp
Time-synchronized MRoPE in Qwen2.5-VL has 2 key limitations:
- by tying temporal position IDs directly to absolute time, the method produces excessively large and sparse temporal position ids for long videos, degrading the model's ability to understand long temporal contexts - 由于将时间位置 ID 直接绑定到绝对时间,对于长视频会产生非常大且稀疏的时间位置 ID,从而削弱模型对长时序上下文的理解能力;
- effective learning under this scheme requires extensive and uniformly distributed sampling across various fps, increasing the training cost - 在这种设计下,要实现有效学习,就需要在不同帧率(fps)下进行大量且均匀分布的采样,这会明显提高训练成本。
Qwen3-VL adopt a textual token-based time encoding strategy, in each video temporal patch is prefixed with a timestamp expressed as a formatted text string(<3.0 seconds>).
During training, generate timestamps in both seconds and HMS formates to ensure the model learns to interpret diverse timecode representations.
Pre-Training
The pre-training methodology is systematically structured into 4 distinct stages.
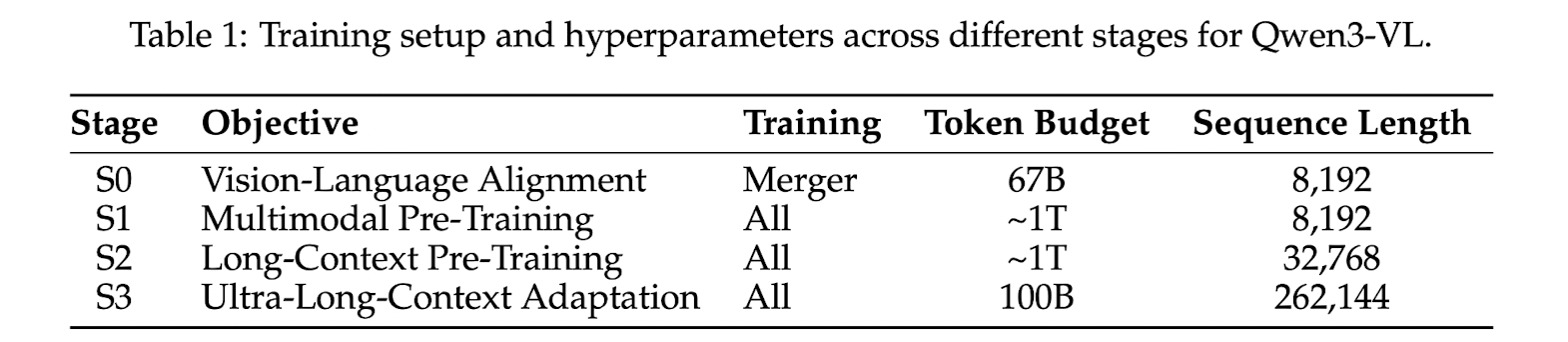
S0: Vision-Language Alignment
- bridging the modality gap between the vision encoder and the LLM
- only train the MLP
- establishes a solid foundation for cross-modal understanding
S1: Multimodal Pre-Training
- full-parameter multimodal pre-training
- VL data and text-only data
S2: Long-Context Pre-Training
- extend the model's contextual processing abilities
- all params continued to be trainable
S3: Ultra-Long-Context Adaptation
- push the model's context window to its operational limits
Post-Training
Three-stage process
SFT
- instruction-following abilities and activates latent reasoning skills
- non-thinking and CoT formats data for different models
Strong-to-Weak Distillation
- using text-only data to finetune the LLM backbone
The distillation process consists of two main phases
- off-policy distillation
- outputs generated by teacher models are combined to provide response distillation
- helps lightweight student models acquire fundamental reasoning abilities, establishing a strong foundation for subsequent on-policy training
- on-policy distillation
- the student model generates the responses based on the provided prompts
- the on-policy sequences are then used for fine-tuning the student model
RL
- reasoning RL and general RL
- SAPO