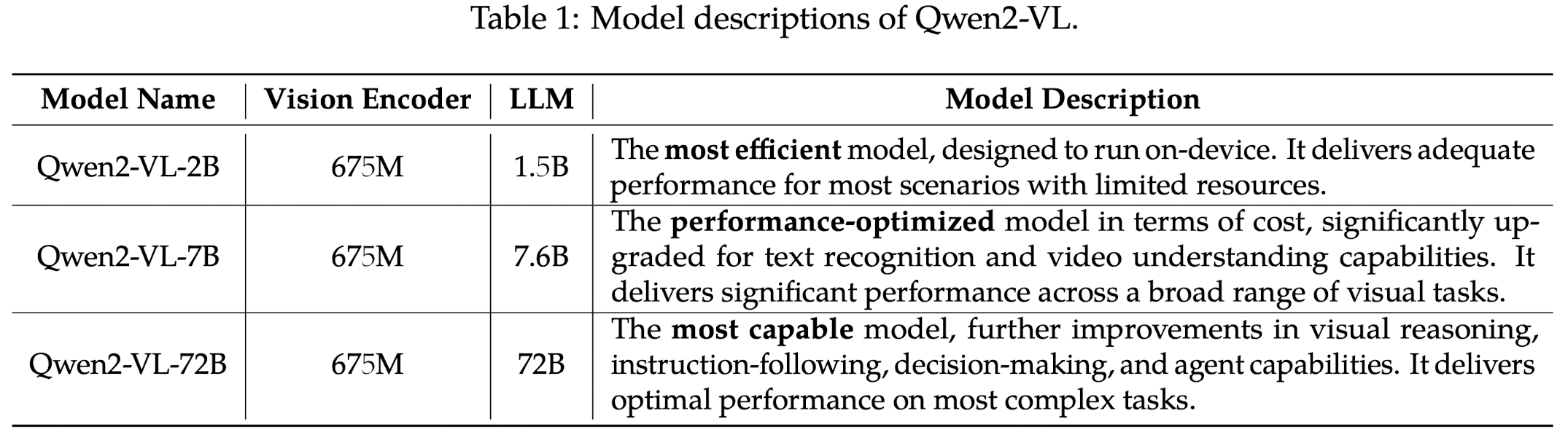
Qwen2-VL introduces
- Naive Dynamic Resolution mechanism: enables the model to dynamically process images of varying resolutions into different numbers of visual tokens 动态将不同分辨率的图像转换成不同数量的视觉 tokens
- Multimodal Rotary Position Embedding(mRoPE): facilitating the effective fusion of positional information across text, images, and videos 促进文本、图像和视频之间位置信息的有效融合
Current Shortcomings
Current LVLMs are typically constrained by a fixed image input size, requiring input images to be a fixed size or employ a scale-then-padding approach, which limits the model's ability to capture information at different scales, leading to a significant loss of detailed information in high-resolution images. LVLMs 受限于 固定的输入图像大小
Most LVLMs rely on a static, frozen CLIP-style vision encoder, the visual representations might not be adequate, particularly for complex reasoning tasks and processing intricate details within images. LVLMs 使用静态、冻结的 CLIP风格视觉编码器,这可能导致视觉表示不足,特别是在需要 复杂推理 和 处理图像细节 的任务中。这种方法可能导致视觉编码器与大型语言模型之间的“认知失调”,即视觉特征超出了语言模型的解释范围。Recent works fine-tuning the ViT during the LVLM training process, yielding improved results. To further enhance, introduces dynamic resolution training, and a 2D Rotary Positional Embedding in the ViT. 采用 动态分辨率训练、在 ViT 中添加 2D-RoPE、在训练过程中微调 ViT 可以改善。
The use of one-dimensional position embeddings in current models significantly limits the ability to model 3D space and temporal dynamics effectively. 1D 的位置编码限制模型在 3D 空间和时间维度上的能力。 Thus, develop the MRoPE, employs components to represent temporal and spatial information. MRoPE 通过引入组件来表示时间和空间信息,增强了模型的视觉表示能力。
Approach
Model Architecture
ViT as the vision encoder, for varies scale adaptations, it has approximately 675M parameters, adept at handling both image and video inputs. The language model is Qwen2 of varies scales.
Naive Dynamic Resolution
Qwen2-VL can process images of any resolution, dynamically converting them into a variable number of visual tokens. Qwen2-VL 可以处理 任意分辨率 的图像,动态转换为不同数量的视觉 token。
- Replace ViT's absolute position embedding with 2D-RoPE to capture the 2D positional information. 替换 ViT 的绝对位置编码 为 2D-RoPE
- At the inference stage, images of varying resolutions are packed into single sequence, with the packed length controlled to limit GPU memory usage. 推理时,不同分辨率大小的图像被 packed 到一个大小受限于 GPU 显存的序列中。
- To reduce the visual tokens of each image, a simple MLP layer is employed after the ViT to compress adjacent tokens into a single token, with the special
<|vision_start|>and<|vision_end|>tokens at the beginning and end of the compressed visual tokens. 为了减少视觉 token 数量,在 ViT 后添加一个简单的 MLP层 将相邻的 token 压缩成一个 token,并在首位添加两个特殊 token<|vision_start|>和<|vision_end|>
的图像,在 patch=14 的ViT后,被压缩为 66 个 tokens。
Multimodal RoPE
M-RoPE effectively models the positional information of multimodal inputs, by deconstructing the original rotary embedding into 3 components: temporal, height, and width. 多模态旋转位置编码(M-RoPE) 是一种针对多模态输入(如文本、图像和视频)设计的高级位置编码方法。通过将原始旋转位置编码(RoPE)分解为三个组件:时间、高度和宽度,来有效地建模多模态输入的位置信息.
- text inputs: utilize identical position IDs, making M-RoPE functionally equivalent to 1D-RoPE; 由于文本是线性序列,所有标记使用相同的位置信息,因此M-RoPE在这种情况下等同于一维RoPE。
- images: the temporal IDs of each visual token remain constant, while distinct IDs are assigned to the height and width components based on the token's position in the image 每个视觉标记的 时间 ID 保持不变,而 高度和宽度组件根据标记在图像中的位置分配不同的 ID。
- videos: the temporal ID increments for each frame, while the height and width components follow the same ID assignment pattern as images; 每帧的时间 ID 递增,而高度和宽度组件遵循与图像相同的 ID 分配模式。
- multiple modalities: position numbering for each modality is initialized by incrementing the maximum position ID of the preceding modality by one. 每种模态的位置信息编号通过将前一个模态的最大位置 ID 加一来初始化,确保不同模态之间的位置信息不冲突。
Unified Image and Video Understanding
Qwen2-VL employs a mixed training regimen incorporating both image and video data, ensuring proficiency in image understanding and video comprehension. Qwen2-VL 采用了 混合训练 方案,结合图像和视频数据,确保模型在图像理解和视频理解方面的能力。 通过这种训练策略,模型能够在图像问答、文档解析、多图像比较、视频理解、视频流对话和基于代理的交互等任务中表现出色。
- to preserve video information as completely as possible, sampled each video at two frames per second 在训练过程中对每个视频以每秒两帧的频率进行采样
- add 3D convolutions with a depth of two to process video inputs, allowing the model to handle 3D tubes instead of 2D patches, ensuring it to process more video frames without increasing the sequence length 处理视频输入时引入了深度为 2 的 3D 卷积,使其能够处理三维的“立方体”数据块,而非传统的二维图像块。这使得模型在不增加序列长度的情况下处理更多的视频帧,提高了视频理解的效率。
- each images is treated as two identical frames 将每张图像视为两个相同的帧,以适应其视频处理架构。